K-NN (K-Nearest Neighbor)
- 새로운 데이터가 기존 어느 그룹에 속하는지 분류하는 것
- 학습 데이터와 비교하여 주위에 가장 많은 데이터가 가진 클래스로 반환을 한다.
- 주위에 k=5개(default)의 점들을 선택하여 비교하여 예측을 한다.
- k값을 변경하여 더 많이 또는 적게 비교할 수도 있다.
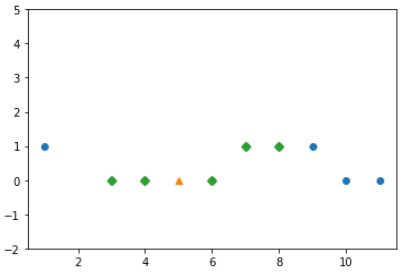
위 그래프로 K-NN을 설명하면 삼각형 의 값을 찾기 위해 가장 가까이에 있는 5개의 마름모 를 찾는다. 그리고 마름모 안에 있는 데이터의 분포를 비교한다. 0이 3개 있고 1이 2개 있다. 0이 1보다 더 많기 때문에 삼각형은 0이 된다.
KNN 코드 (sklearn)
- from sklearn.neighbors import KNeighborsClassifier
- sklearn.neighbors모듈 안에 있는 KNeighborsClassifier함수를 가져와 사용한다.
- kn = KNeighborsClassifier(n_neighbors=n)
- n개 이웃을 기준으로 예측을 한다. n_neighbore가 없으면 5개로 예측을 한다.
- kn.fit(x, y)
- fit()로 학습을 한다.
- kn.score(x, y)
- score()로 정확도를 확인한다.
- kn.predict([[n]])
- predict()로 새로운 데이터의 target(y)을 확인한다.
from sklearn.neighbors import KNeighborsClassifier
#데이터 설정 및 전처리
x=np.array([1,3,4,6,7,8,9,10,11])
y=np.array([1,0,0,0,1,1,1,0,0])
x = x.reshape(-1,1)
y = y.reshape(-1,1)
#knn 코드
#5개 이웃을 기준으로 예측을 한다.
kn = KNeighborsClassifier(n_neighbors=5)
#fit()함수로 주어진 데이터를 학습한다.
kn.fit(x, y)
#score()로 정확도를 확인한다.
kn.score(x, y)
#predict()로 새로운 데이터의 정답을 확인한다.
kn.predict([[5]])
#이웃을 구한다.(이웃까지의 거리와 이웃의 인덱스를 반환)
distances, indexes = kn.kneighbors([[5]])
#그래프로 표현
plt.scatter(x,y)
plt.scatter(5, kn.predict([[5]]), marker='^')
plt.scatter(x[indexes,0],y[indexes,0],marker='D' )
plt.ylim(-2,5)
plt.show()
출력
-> 다섯 개의 점(마름모)를 기준으로 삼각형의 값을 예측한다.
K-NN Regression(K-최근접 이웃 회귀)
- 회귀: 회귀는 분류하는 것이 아니라 임의의 숫자로 예측을 하는 것이다.
- k-최근접 이웃 회귀는 이웃한 근접한 값의 평균을 내어서 예측하는 것이다
- k-최근접 이웃처럼 k값을 지정하여 근접한 수를 지정하여 예측할 수 있다.
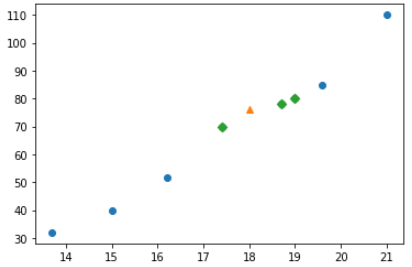
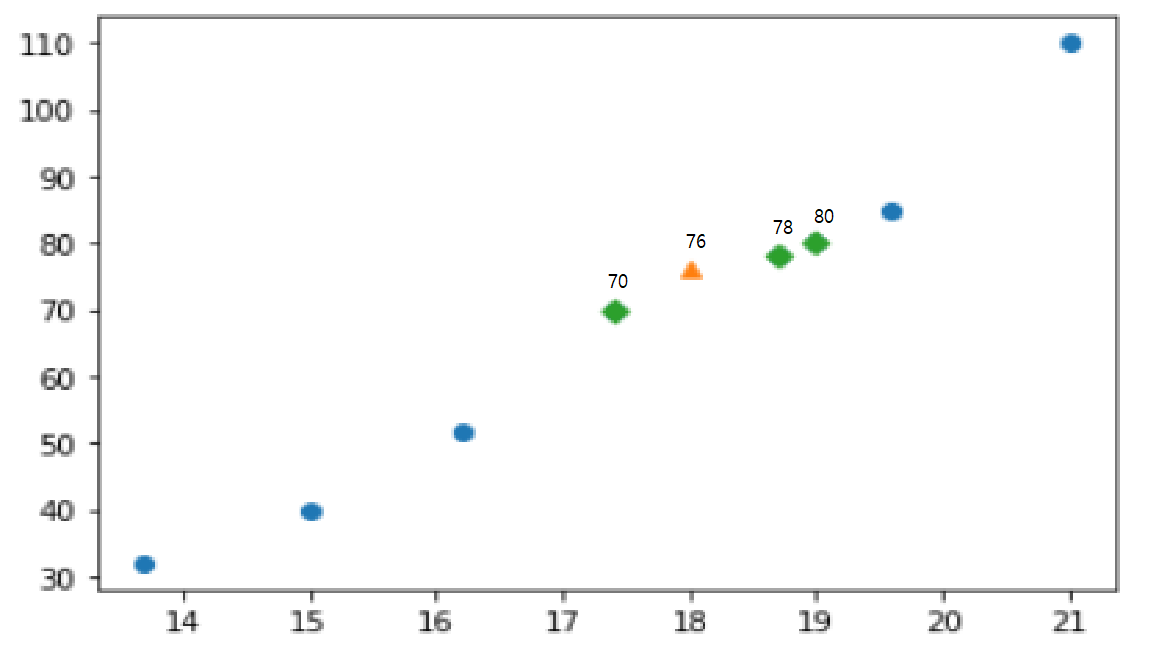
- k=5개 이웃한 값이 아래와 같을 때 삼각형 의 값은 (50+50+50+60+60)/5 = 54로 예측할 수 있다.
KNN Regression 코드 (sklearn)
- from sklearn.neighbors import KNeighborsRegressor
- sklearn.neighbors모듈에 있는 KNeighborsRegressor함수를 가져와 사용한다.
- knr = KNeighborsRegressor(n_neighbors = n)
- 가장 가까운 n개의 데이터로 regression(회귀)를 한다. n_neighbors=n이 없으면 5개로 regression을 한다.
- knr.fit(x, y)
- x, y데이터로 학습을 한다.
- knr.predict([[n]])
- n 데이터의 target(y)을 확인한다.
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
x = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,])
y = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,])
train_input, test_input, train_target, test_target = train_test_split(x, y, random_state=42)
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
knr = KNeighborsRegressor(n_neighbors = 3)
knr.fit(train_input, train_target)
print(knr.predict([[18]]))
distance, indexes = knr.kneighbors([[18]])
plt.scatter(train_input, train_target)
plt.scatter(18, 76, marker ='^')
plt.scatter(train_input[indexes],train_target[indexes], marker='D')
plt.show()