1. 주제 선정이유
- 투자자들이 자신들의 포트폴리오를 구성할 때 참고하는 지표로 기업 신용등급을 많이 본다. 기업 신용등급은 10개의 등급으로 투자를 하기에 적격한지 판단하기 어렵다.
- 심지어 신용등급은 발행되기 시간과 비용이 들기 때문에 지금 당장 투자자들이 확인할 수 없다
- 딥러닝을 이용하여 투자적격인지 비적격인지 예측하는 모델을 만들었다.
- 본 모델을 이용하여 투자자들이 포트폴리오를 구성할 때 참고할 수 있는 지표로 사용될 수 있도록 도움을 주기위해 선정하였다.
2. 데이터
기업 신용등급은 재무적 평가요소와 비재무적 평가요소로 평가를 하여 등급을 메긴다.
일반 사용자들이 재무 데이터를 쉽게 구할 수 있으므로 재무적 평가요소로 데이터를 수집하였다.
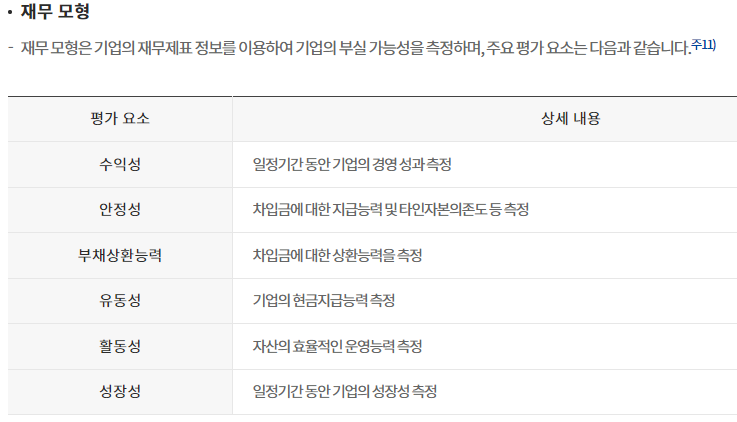
평가 요소 중 성장성, 수익성, 안전성, 활동성을 분석하여 8개의 지표로 분석을 하였다.
2.1 데이터 수집
- 일반 사용자들이 쉽게 조회할 수 있는 것을 목표로 일반인들이 쉽게 조회할 수 있는 재무적 요소로 기업 건전성을 예측하였다.
- DART에서 제공하는 재무제표를 수집하고, 8개의 평가 요소로 분석하여 총 8개의 특징(Feature)로 구성하였다.
- NICE 신용평가에서 제공하는 기업 신용등급을 기반으로 건전 클래스(0) / 비건전 클래스(1)으로 나누어 각각 수집하였다.
2.2 데이터 분석
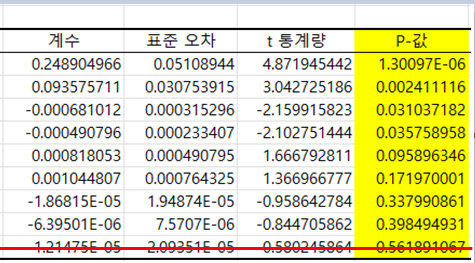
- 각 특징(Feature)들이 클래스(Class)에 영향을 미치는가를 분석하기 위해 회귀 분석을 하였다.
-
회귀 분석을 통해 P-값이 가장 큰 특징을 제거하였다.
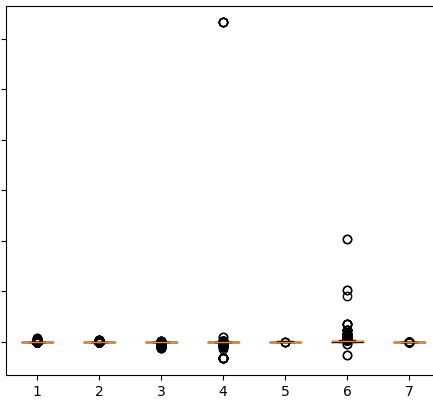
- 다음으로 나머지 데이터들에서 이상치가 있는 지 Boxplot를 이용하여 확인하였다.
- Boxplot을 이용하여 이상치가 있는 4, 6 특징을 제거하였다.
- 총 5개의 특징을 가지고 학습을 하였다.
3. 모델 선정
학습 모델을 선정할 때 머신러닝과 딥러닝 중 고민을 했었다.
[이현상, 오세환 “머신러닝 기법을 활용한 기업 신용평점 예측모델 개발”, 한국경영정보학회, 2019] 논문을 보면서 머신러닝이 딥러닝보다 높은 정확도를 달성한 것을 보면서 “좀 더 똑똑한 결정을 내릴 수 있는 딥러닝이 왜 머신러닝보다 정확도가 낮지?” 라는 궁금증으로 DNN을 선택하여 진행하였다.
DNN(Deep Neural Network)
- 연속형 데이터를 쉽게 분석 가능하다.
- 예측하는 능력이 다른 모델보다 우수하다.
-> 이러한 장점 때문에 DNN을 이용하였다.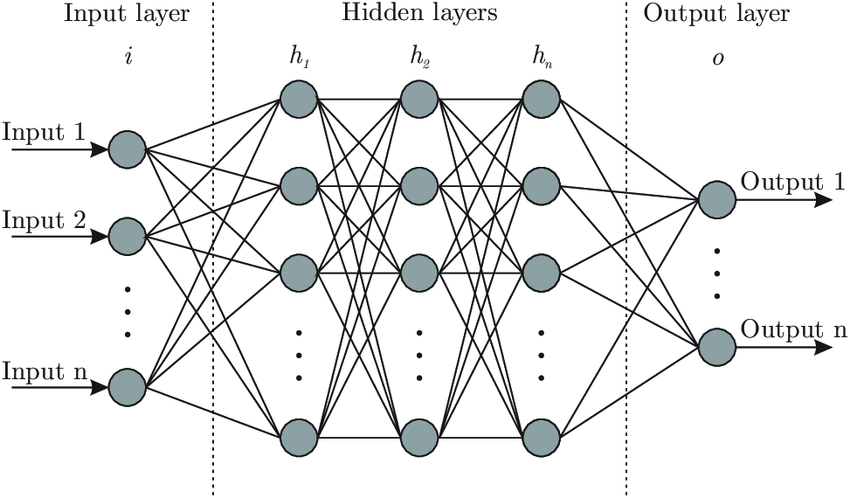
3.1 학습 테크닉
<오버피팅을 해결하기 위한 방법>
학습을 하는 중간에 train의 정확도는 높아지지만 test의 정확도는 그리 높지않은 것을 발견하게 되었다. 말로만 들었던 오버피팅이 발생하게 된 것이다.
오버피팅을 해결하기위해 데이터의 수를 증가시키거나 모델 복잡도 줄이기, 드롭아웃과 같은 학습 테크닉을 사용하는 것이었다.
데이터를 증가시키기엔 다소 시간이 거리기 때문에 복잡도 줄이기, 학습 테크닉을 사용하기로 했다.
-> 배치정규화, 드롭아웃, Learning Rete Scheduler를 이용하여 DNN이 학습하는 동안에 오버피팅이 발생하지 않도록 하였다.
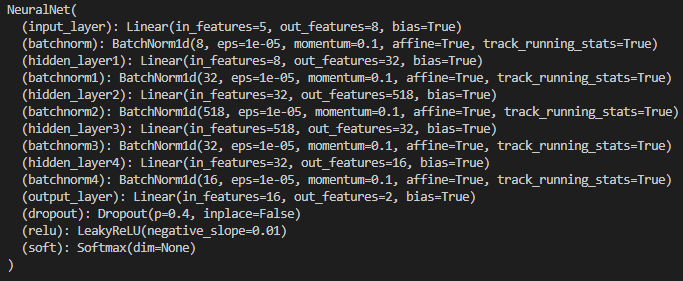
은닉층을 4개로 지정을 하였다. 은닉층을 2개로 하였을 땐 학습을 제대로 하지 못하는 것을 보았고, 4개 이상으로 학습을 하였을 때도 좋지는 못하였다.
각 입력층 은닉층 출력층에는 배치정규화를 사용하였고 활성화 함수는 ReLU를 사용하였다.
손실함수로 CrossEntropyLoss를 사용하기 때문에 출력층에는 활성화 함수를 사용하지 않았다. (Pytorch에서 제공하는 CrossEntropyLosss는 softmax와 cross entropy를 합쳐놓았기 때문이다. )
1) 배치정규화(Batch Normalization)
- 각 층의 활성화 함수의 출력값 분포가 골고루 분포되도록하는 방법으로, 각 층에서 활성화 함수 출력값이 정규분포를 이루도록 하는 방법이다.
2) 드롭아웃(Drop Out)
- 학습 도중 일부의 노드의 값을 0으로 만들어 정해진 확률로 뉴런을 제거하는 방법이다.
3) Learning Rate Scheduler
- 학습률을 학습 중에 낮게 바꾸거나, 학습중 발생하는 Loss에 따라 학습률을 변경하여 학습하는 방법이다.
4. 모델 학습
배치정규화와 드롭아웃가 있을 때와 없을 때의 차이가 있었다. 정확도 차이가 대략 약 10%정도가 있었던 것으로 기억을 한다.
배치정규화로 각 layer에서의 활성화값이 잘 분포가 되고, 드롭아웃으로 layer의 노드를 줄이므로인해 오버피팅을 방지하였다고 생각한다.
이번 프로젝트를 하면서 Learning rate scheduler를 처음 알게 되었다. 다양한 Learning rate scheduler 중 ReduceLROnPlateau를 사용하였다. ReduceLROnPlateau는 Validation에서 발생하는 loss가 지정된 epoch마다 감소하지 않으면 자동으로 학습률을 감소시키는 것이다.
from torch.optim import lr_scheduler
# factor은 Learning rate를 감소시키는 값이고
# patience는 지정된 수만큼 epoch 동안 loss가 감소하지 않으면 Learning rate를 감소시킨다.
# threshold는 이전 epoch보다 지정된 값보다 작으면 Learning rate를 감소시킨다.
# eps는 Learning rate의 최소값을 설정한다.
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=5, threshold=0.001, threshold_mode='rel', min_lr=0, eps=1e-11, verbose=False)
아래의 그래프는 ReduceLROnPlateau를 사용하면서 나온 Training 그래프이다.
epoch가 많아서 잘 보이지 않지만 loss가 증가할 거 같으면 Learning rate를 줄여 loss가 꾸준히 감소하는 것을 볼 수 있고, 결과적으로 정확도가 높아지는 것을 볼 수 있다.
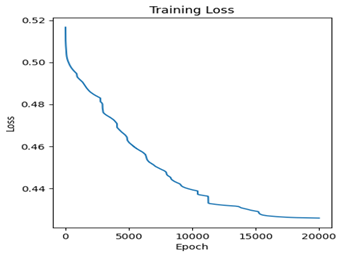
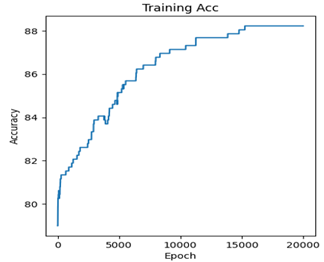
- 학습 테크닉을 사용하면서 학습을 하니 Loss가 꾸준히 감소하고 traning정확도도 꾸준히 증가하는 것을 알 수 있고 최종 test 정확도는 84%를 달성하였다.
- 또한 DNN의 단점인 Overfitting도 발생하지 않는 것을 알 수 있다.
5. 사용한 skills
Python Pytorch Scikit-learn Matplotlib Pandas